ZPF: Patented Innovation in Distributed Computing
Zero Point of Failure (ZPF) is our patented technology, designed to ensure maximum uptime, rapid recovery, and persistent service even during outages.
Originally conceived by Anomify’s Gary Wilson for the ad technology sector, it is designed to significantly enhance infrastructure reliability and ensure continued service. This innovative solution addresses the critical need to prevent service disruptions often caused by cloud provider outages, which pose substantial operational risks.
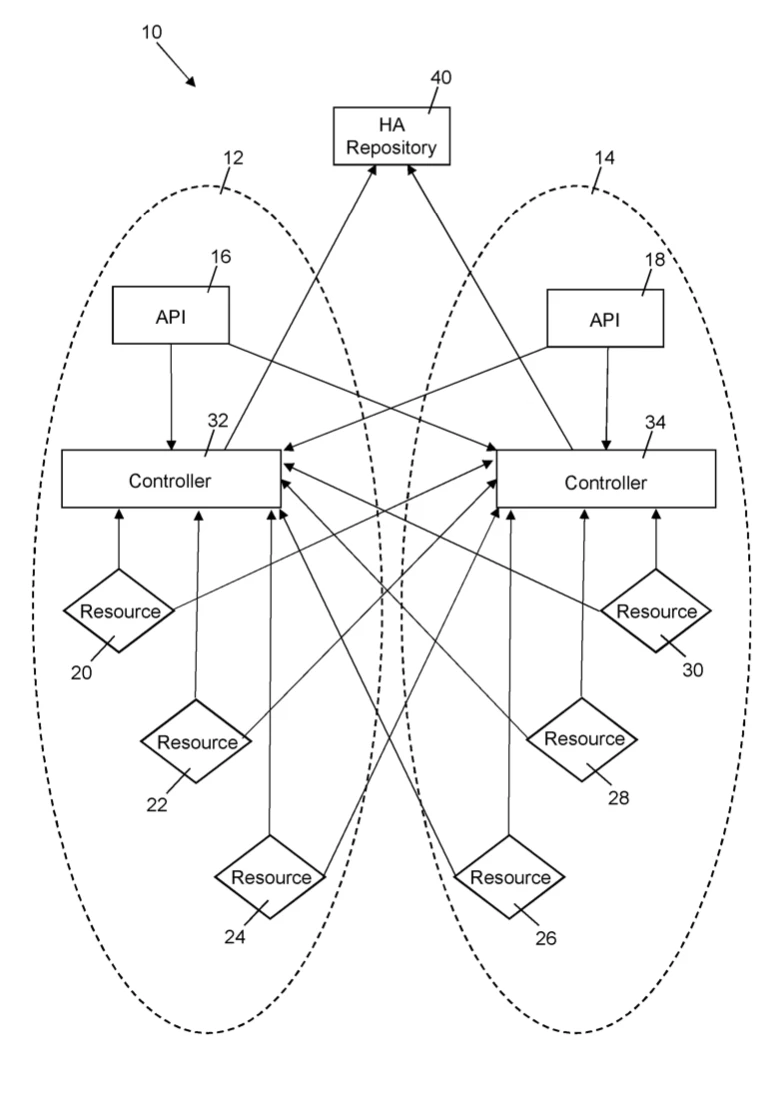
At its core, ZPF is an advanced distributed computing system that internally manages server infrastructure for both content serving systems and internal operational tools. The innovation lies in its architecture, which makes infrastructure components fundamentally interchangeable across diverse cloud providers. This eradicates dependency on any single provider, enabling swift isolation of issues and rapid recovery in the event of failures.
The system is designed to maintain a persistent level of service even when management interfaces of a computing environment become unavailable.
Key Innovations and Features of ZPF:
Distributed Control Enhances Resilience
Each individual computing environment within the ZPF system is equipped with a local controller capable of managing all computing resources across the entire distributed system. This means if one controller or environment fails, another can seamlessly take over, ensuring continuous operation.
Provider Agnosticism and Abstraction
ZPF intelligently abstracts the specific details of different cloud provider APIs. This allows applications like web and database servers to be deployed and run consistently, irrespective of the underlying provider, ensuring the same functionality across varied environments.
Dynamic Resource Optimization
The system facilitates dynamic reconfiguration, allowing for the provisioning and re-provisioning of computing resources from a mix of providers. This enables the selection of the most cost effective and best performing resources to meet specific requirements, optimizing the performance to cost ratio.
Proactive Failure Management & Data Integrity
Local controllers maintain cache copies of metadata from provider APIs and local copies of the global repository. In the event of an API or global repository failure, these cached versions are used, allowing for persistent service and rapid reprovisioning of resources. Computing resources are also “high availability aware,” programmed to automatically failover to an alternative controller if their primary controller fails.
Automated System Management:
- High Availability Core Services: ZPF ensures its own core components, such as configuration management, code repositories (like Git or SVN), and orchestration systems (like Puppet, Chef, or SSH based tools), are themselves highly available.
- Self Documenting Infrastructure: The system automatically tracks deployed resources by their identifiers and commits this information to a global high availability repository. This repository is linked to an integrated ticketing system, which automatically generates documentation from commit logs, making all resources self documenting.
- Secure and Standardized Services: Each local controller provides secure configuration management services, secure orchestration services, and custom software repositories (like Yum or APT) to the computing resources.
This robust and adaptable approach to distributed computing proved sufficiently novel and impactful to warrant official patent protection. First conceived to tackle the challenges of cloud dependencies in 2012, ZPF’s sophisticated architecture continues to be a cornerstone of our highly reliable operations.