Analysis Models
Anomify is a machine learning anomaly detection platform designed for real-time, high volume environments. We’ve built on existing leading detection algorithms and developed our own highly sophisticated proprietary models in order to serve the most appropriate algorithms for monitoring different types of data.
Over more than 10 years we have built these tools and earned our domain knowledge through hard graft, novel experiments, maths, geometry and science. We are masters at pattern recognition and the application of machine learning in monitoring.
Our background in high volume real time environments demanded innovative approaches to monitoring at scale, to reduce false positives and save us from alert fatigue. We too shared the experiences we see across our customers and developed the Anomify product to best solve these challenges.
It’s about seeing value quickly, reducing time to resolution but above all surfacing hidden events you might otherwise have never found.
Anomify’s analysis approach
Our detection pipeline is broken down into three progressive stages, each increasing in complexity and accuracy, to reduce false positives and surface the most important events.
Stage One: Real-Time Detection
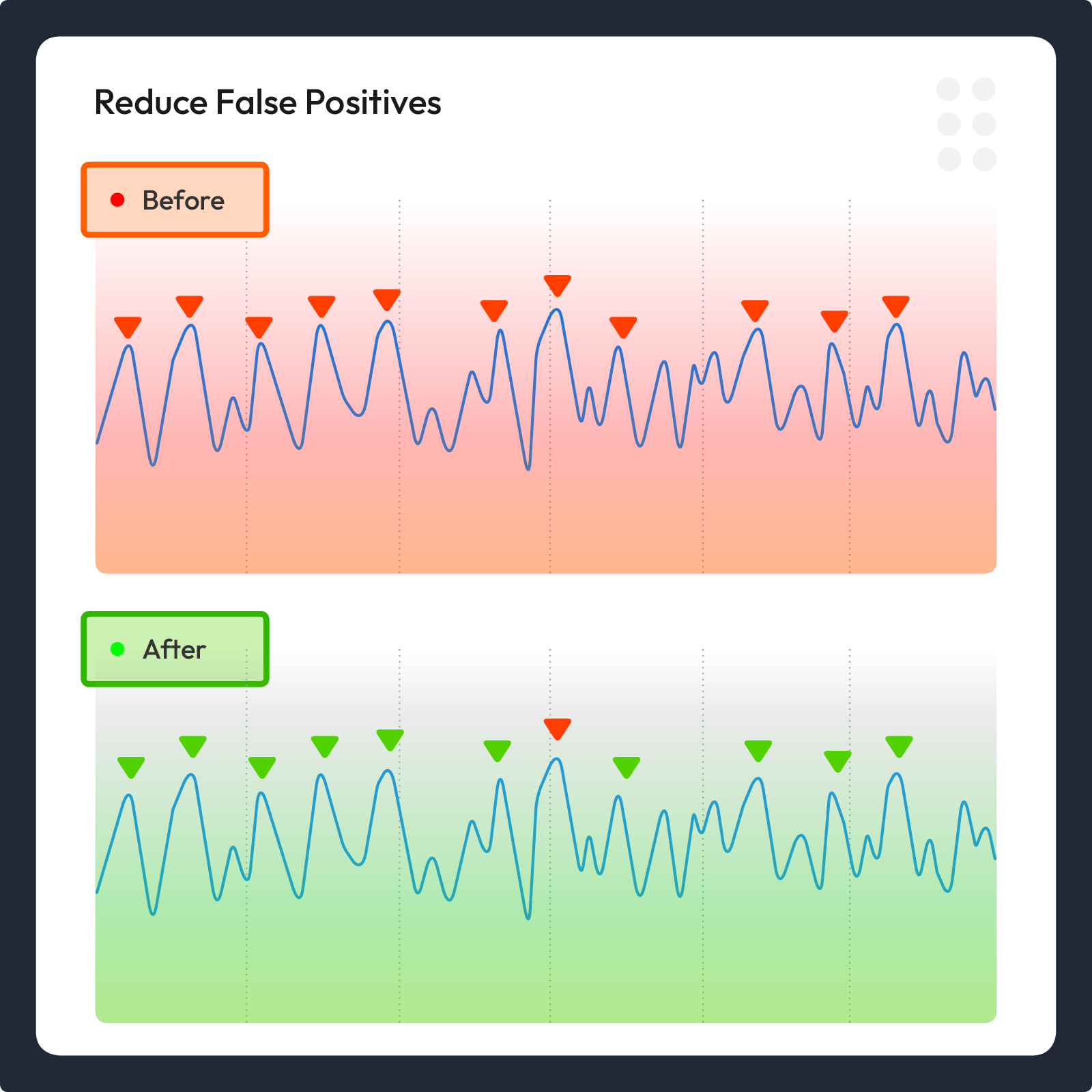
Approach: At ingestion, Anomify applies fast, unsupervised statistical techniques to identify early anomalies across streams of time series data.
Purpose: Speed and scope. Capture everything suspicious in milliseconds.
Stage Two: Focus on Contextual Filtering
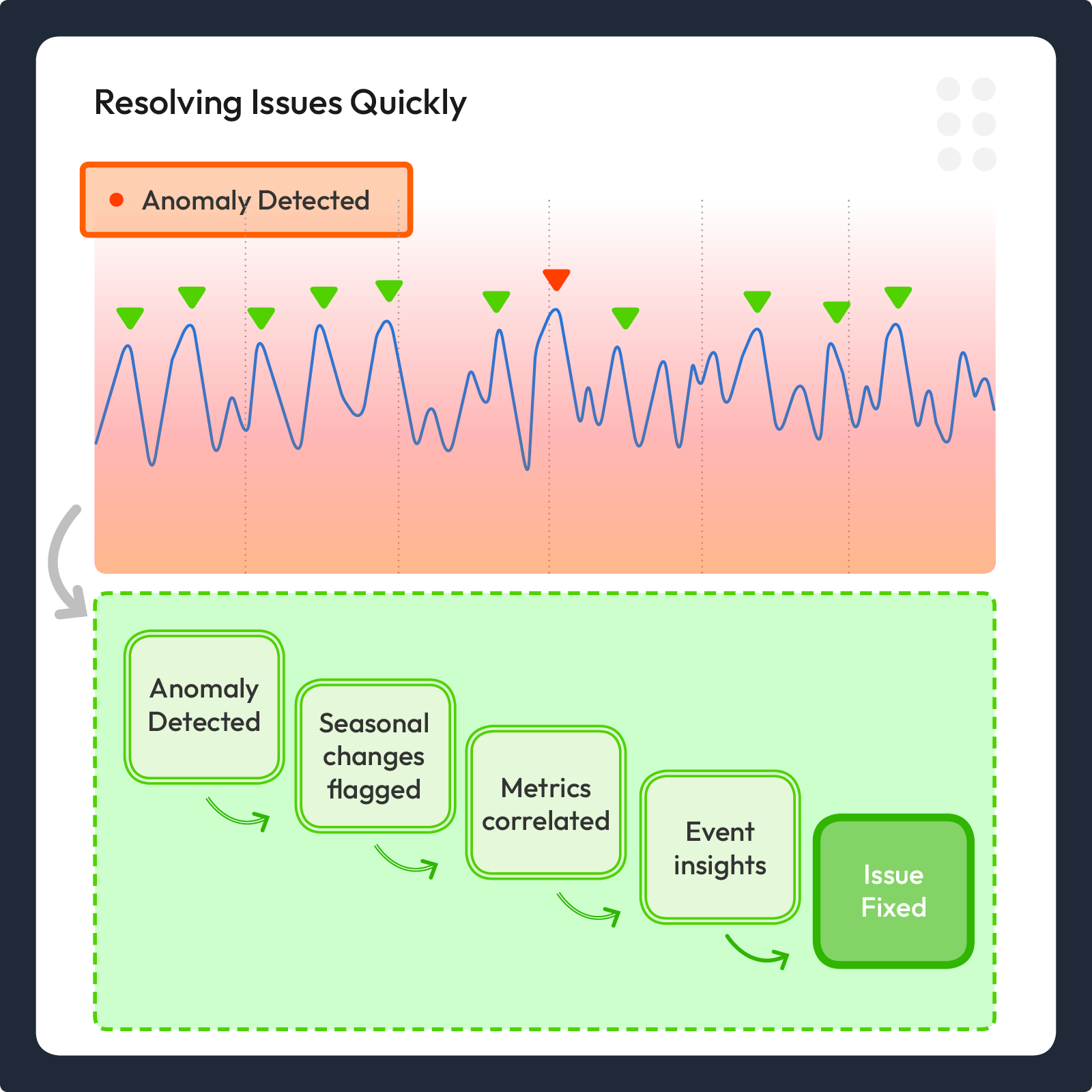
Approach: Using logic and pattern recognition to filter out false positives, correlate metrics and determine root cause.
Purpose: Reduce noise while preserving true anomalies.
Stage Three: Supervised Learning with Feedback
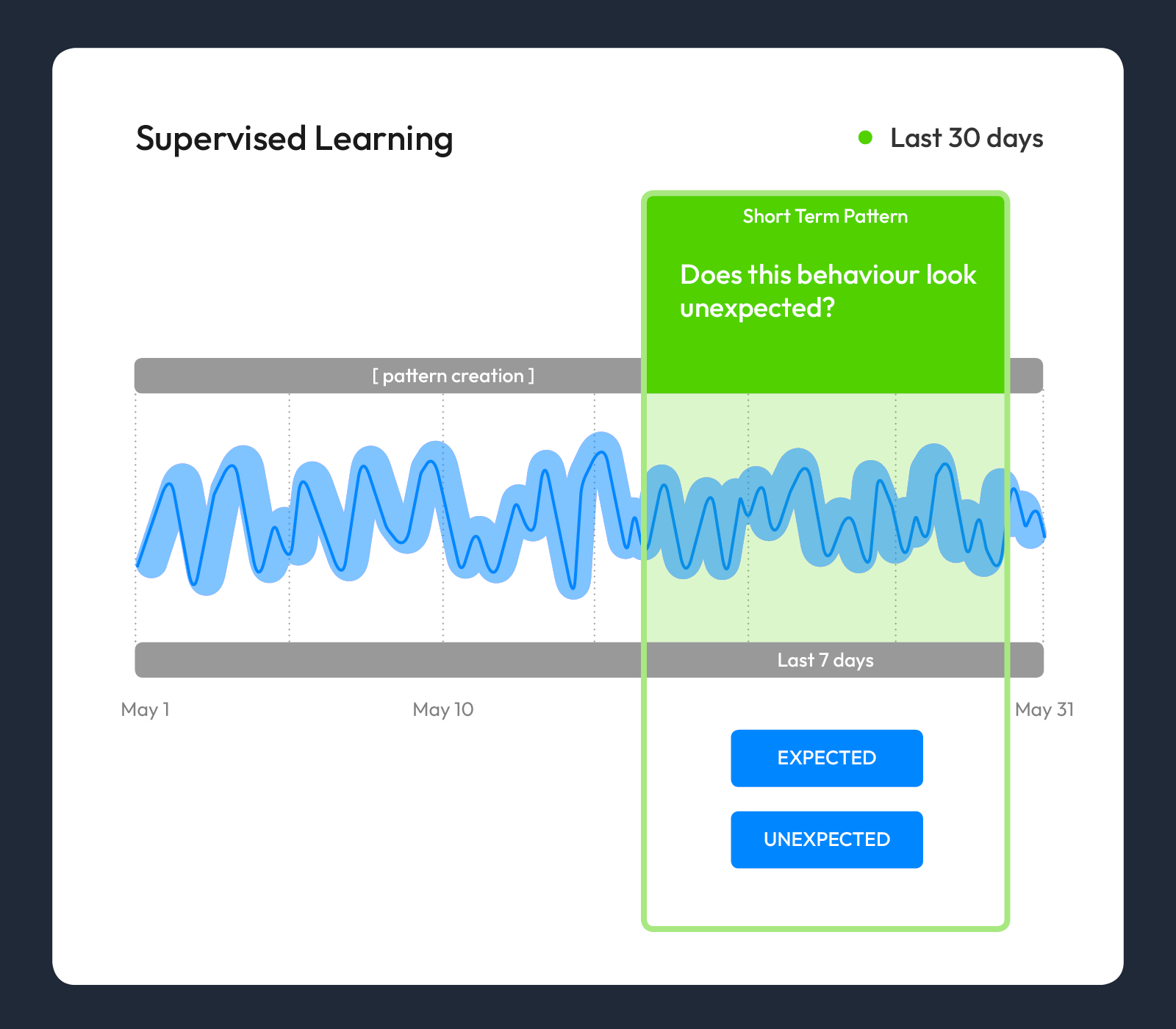
Approach: Anomify’s pipeline can automatically recognise repeating patterns. Users can also create patterns through supervised learning, manually selecting a section of time-series which is behaving as you would expect. This training and identification of false positives improves the model accuracy and enables an ever greater filtering of alerts.
Purpose: Ensures that only the highest value events gets notified as alerts with a high confidence.
Tools currently in Beta:
- LLMify Anomify service that monitors and analyzes LLM usage across platforms like OpenAI, Anthropic, and AWS Bedrock, providing real-time detection and alerts for abnormal token activity to help organizations manage and prevent misuse in production LLM applications.
- Generative AI assistant in dashboard for querying data with human readable results
- Advanced clustering and correlation methods
Talk to your account manager today about access.
Performance
Anomify’s battle tested performance gains from this staged analysis approach can be seen with:
- 99.01% supervised model accuracy (Stage 3)
- >90% reduction in false positives
- Less than a minute end-to-end latency for real-time alerting
- Supports event-based, metric-based & hybrid telemetry
Built on Proven Foundations
Anomify extends concepts from the open-source EarthGecko Skyline:
- Modular detection engines:
analyzer,mirage,luminosity - Real-time metric ingestion
- Redis + Graphite architecture for speed
We’ve added:
- Supervised pipelines
- Proprietary algorithms
- Root cause analysis and correlation
- Feedback loops
- Explainability & user training interfaces
Comparisons with other tools
NEW Try out our new benchmarking tool - Compare
Anomify adds an additional dimension to your monitoring/observability set up. Where generally you have rules and thresholds set on things, Anomify monitors all your metrics in the background, keeping an eye on everything.
Rules, thresholds and SLO (Service Level Objective) calculations do not necessarily aid in pinpointing what changed and where – in fact they exclude most metrics. Anomify monitors all metrics and identifies and records abnormal changes, giving you deep insights into your systems and applications when you need it.
Users in your organisation can train Anomify to recognise expected patterns, just as they would. This reduces false positive anomalies.
Most anomaly detection platforms use unsupervised learning, which creates a disconnect between the user and the model which makes the anomaly assessment. Anomify’s transparent supervision provides a human explanation for the predictions it makes. Predictions can be amended to fit with your mental model of how the system should behave under normal conditions.
How do we store data?
It depends on the data source we are receiving metrics from. Each source varies in the types of data they support and frequency at which they are stored.
Anomify is not a metric store. For efficiency Anomify preprocesses raw metric data it receives every minute. It stores the processed data for analysis and dumps the raw values.Therefore the metric values recorded by Anomify may not exactly match those recorded in your metric store, but behaviour and trends will be the same.
Anomify stores metric data at a frequency of one data point per minute. How we store data and for how long depends on the data source – it can be anywhere from 30 days with Prometheus/Influxdb/victoriametrics data to as long as 2 years with Graphite and other data sources.
We also store the sections of time series that have been trained on indefinitely for pattern matching.
Does it scale?
We built Anomify with scale in mind and have tested with billions of data points. There is no upper limit on metrics, and we can scale horizontally to meet your needs. But it’s worth noting that tracking all metrics all of the time might not be the best approach to your monitoring. Get in touch to discuss your setup.
Have a question? Get in touch to talk to one of our devs - Contact